












[NDC19]알파고와 달랐던 '블소 비무 AI', 엔씨소프트 '블소 비무' AI는 어떻게 만들어졌나
등록일 2019년04월25일 11시45분








지난 해 가을 진행된 '2018 블레이드 & 소울 월드 챔피언십' 현장에서는 전세계 내로라하는 역사 프로게이머들과 정보가 하나도 알려지지 않은 한 유저와의 블라인드 매치가 진행돼 유저들의 관심을 모은 바 있다.
양쪽 모두 경공 금지 제한속에 경기가 진행되기는 했지만 선수들과 대결한 이 비밀스러운 유저는 나름 호각세로 선수와 맞붙었고 심지어는 최성진 선수와 맞붙은 마지막 경기에서는 2:0으로 승리를 따내는데 성공했다.
경기가 다 끝나서야 공개된 유저의 정체는 바로 엔씨소프트가 개발한 비무 AI. 이들의 경기를 보았던 많은 유저들은 높은 수준의 블소 비무 AI에 놀라움을 나타낸것은 물론 블소 비무 AI가 어떻게 제작 됐는지 궁금해했다.
그리고 약 6개월여가 지나서 그에 대한 궁금증을 해결해 줄 수 있는 강연이 NDC에서 진행됐다.
엔씨소프트 게임 AI 랩 강화학습팀의 문상빈씨가 '강화학습을 이용하여 프로게이머 수준의 블소 비무 AI 만들기'라는 이름으로 진행한 강연을 통해 지난 해 블소 월챔에서 선보였던 AI 캐릭터들의 학습 과정과 그 결과에 대해 공개한 것.

엔씨소프트는 강화학습을 진행하기 전 AI에 입력할 규칙 수립을 먼저 했다. 블소 비우의 경우 3분이라는 제한 시간, 상대의 HP를 0으로 만드는 목표(제한 시간이 지난 경우 HP가 더 많은 유저가 승리한다), 아이템이나 스탯 차이가 없는 동등한 조건의 표준 셋팅을 AI에 적용했다.
그 과정에서 수동으로 규칙을 짜면 여러 부분에서 허점이 발생했기 때문에 수동으로 AI의 규칙을 짜는 대신 강화학습을 통해 허점을 최소한으로 줄임과 동시에 이벤트 매치를 앞두고 AI를 공격형, 밸런스형, 수비형으로 나누고 각각의 학습을 시작했다.
그에 따르면 AI의 직업은 역사로 고정했는데 매번 블소 리그에 출전하는 직업이기도 했고 역사의 대부분의 스킬이 근거리 스킬이어서 AI 연구가 용이했기 때문.
엔씨소프트는 강화학습 단계를 크게 두개로 나누었다. 에이전트가 현재의 상황을 판단할 수 있는 관측(HP, 내력, 거리, 스킬 쿨타임) 단계와 이 값을 바탕으로 해야 하는 액션을 판단하는 행동 단계이다.
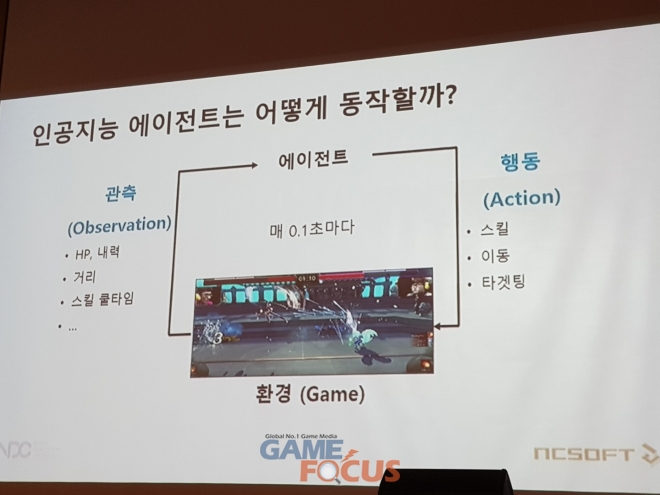
블소의 경우 직업마다 무공과 특성 및 능력치가 다르기 때문에 행동 단계를 위해 행동을 각각의 범주로 나누고 도식화하는 작업이 필요해다.
물론 이 과정에서 몇 가지 문제가 발생하기도 했다. '알파고'와 이세돌의 대결로 국내외에 AI의 발전도를 알렸던 바둑과 비교해 블소의 경우 더 많은 행동 패턴, 스킬 이동 및 타겟팅과 같은 변수가 존재하는 등 계산해야 하는 내용이 더 복잡했던 것.
여기에 바둑은 한 수당 60초라는 시간이 주어지지만 블소 비무의 경우 0.1초라는 아주 찰나의 시간만 주어지기 때문에 바둑처럼 상대의 수를 예측하면서 진행하는 탐색 기반의 AI 방식은 적절하지 않아 인공 신경망을 도입, 순간적인 계산이 빠르게 되도록 제작했다.
또한 실제 프로게이머의 플레이 스타일은 다양하고 어떤 상대를 만나게 될지 모르므로 엔씨소프트 강화학습 팀은 먼저 미지의 상대에게 최적의 대응을 위해 다양한 상대 캐릭터를 만들고 이들을 상대로 끊임없이 학습하면서 상대에 대한 일반화 작업을 진행했다고 밝혔다.
여기서 두 번째 문제가 발생했다. 단순히 전투만으로 학습하면 AI가 원치 않는 방향으로 학습하고 성장할 수 있기 때문에 강화학습 팀은 보상 시스템을 통해 AI들의 높은 성능을 유지하는 방향으로 가닥을 잡았다.
그는 이해가 쉽도록 아이의 걸음마를 예로 들었다. 아이가 계속 넘어지면서 걸음마를 배우는 것처럼 옳게 행동하는 것과 그르게 하는 것에 각각에 점수를 주고 학습 목표를 보상의 합을 최대화하는 것으로 설정하는 것이다. 이를 통해 AI의 에이전트는 좋은 행동들은 지속적으로 강화하고 나쁜 행동들은 약화시키면서 점차 더 강한 AI를 완성하는데 성공했다.
뒤이어 그는 추가 보상을 설정했던 과정에 대해서도 설명했다. 가장 큰 보상 점수를 얻을 수 있는 방법은 승리이지만 승리는 모든 경기가 끝나야 받을 수 있는 드문 보상으로 설정하고 최우선 보상으로 HP의 득실에 함수를 적용했다.
여기에 더 리드미컬한 움직임을 위해 HP, 거리, 시간 등 각각의 패널티를 적용해 각각의 상황마다 에이전트의 행동 값이 다르게 나타나도록 조정했다. 이후 강화학습팀은 매번 결과값을 다르게 낸 에이전트를 일정 시간마다 저장하고 이를 또 다른 더미 파일로 제작해 매번 과거의 자신과 싸우며 AI를 학습 시켰다.

마지막으로 그는 이렇게 학습 시킨 AI의 전투 결과도 공개했다.
먼저 같은 더미 파일을 상대로 처음 학습시킨 AI가 HP를 0으로 만드는데 124초가 걸린 반면 일주일 학습 시킨 AI는 20초 정도로 속도가 빨라졌다. 이는 처음에는 상대에 대한 정보가 없어 갑자기 회피기를 쓰는 등의 불필요한 무빙이 존재했지만 지속된 학습으로 이 같은 것들이 크게 줄었기 때문이다.
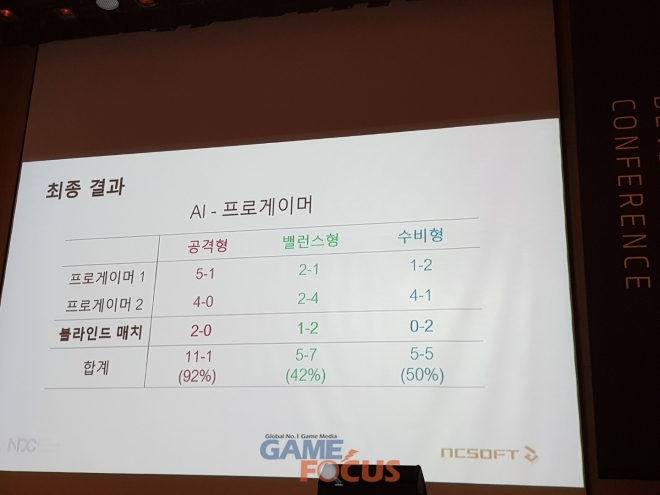
실제 대회에서 선보인 모델은 2주간 학습 시킨 모델로 블소 월드챔피언십 개최 전 진행한 손윤태, 김신겸 선수와의 사전 테스트에서 공격형 AI는 9:1(승률 90%), 밸런스형 AI 4:5(44%), 수비형 AI 5:3(63%)를 보였고 블라인드 매치에서도 공격형 AI가 최성진 선수를 2:0으로 잡아내는 등 유의미한 결과를 얻어냈다.
다음은 Q&A를 정리한 것이다.
보상 학습 수치가 적절하지 않으면 이상한 행동만 할 것 같은데 어떻게 적절한 수를 잡았나
처음에는 보수적으로 확실한 보상만 주려고 했다. 절대적인 값과 상대적인 값 모두 중요한데 “승패의 값이 10일 때 거리에서는 몇을 줘야 승패에 영향을 주지 않고 거리를 좁힐까”와 같이 이런 세부 수치를 조절하는데 어려움이 많았다. 적절한 양은 역시 계속 노력해서 찾았고 보상을 최대한 보수적이고 적게 주면서 찾으려고 했다.
강화학습 프로젝트를 진행할 때의 서버 환경은 어떻게 되나
정확히 기억나지 않지만 우리가 사용한 서버는 1080이 네개 달린 서버 세대였다. 여기에 시뮬레이션을 돌릴 수 있는 PC를 조금 더 추가했다. 다른 프로젝트에 비해 자원이 많지 않지만 2주 동안 4년치의 경험을 쌓을 수 있는 속도로 진행했다.
현재 공개된 AI는 역사 뿐인데 다른 직업으로 학습을 확장할 경우 현재 학습을 진행 중인 AI에서 확장을 하는건가? 아니면 별도의 다른 직업에 맞는 AI를 제작하는가
이 부분은 아까 연구를 소개할 때 말했다시피 일단은 역사로만 캐릭터를 한정했고 다양한 직업에 대한 연구는 아직 진행 중이다. 하나의 AI를 할 수도 있고 조합에 따라 여러 AI를 만들 수도 있는데 더 연구가 필요해 보인다.
비무 AI의 반응 속도가 인간에 비해 너무 빠르다는 생각이 든다
실제로 대회에서 이를 고려한 반응 속도 딜레이를 넣었음에도 불구하고 사람은 애니메이션을 보고 반응 하는데 시간이 필요한 반면, AI는 애니메이션이 아니라도 판단이 가능해 최대한 공정하기 위해 딜레이 외에도 여러 노력을 기울이고 있다.
업데이트나 밸런스 조절을 통해 스킬의 스펙 등이 바뀌면 AI도 다시 학습해야하나
업데이트 상황에 따라 달라지기는 하지만 대회 당시에는 대회에 맞춰 비무 환경을 고정하고 2주동안 학습을 진행한 것이다. 정식 서비스에서 선보인다면 역시 지속적으로 업데이트를 해야 하는데 이와 관련해 트랜스퍼라는 또 다른 연구팀에서 작업을 진행하고 있지만 이 자리에서 자세한 설명은 힘들 것 같다.
역사 캐릭터가 아닌 다른 캐릭터와의 전투에서는 어떤 결과가 나왔는가
아직 시도조차 하지 않았다. 역사 VS 역사의 학습을 마스터하고 다른 직업에 대한 연구를 진행할 생각이기 때문에 지금은 연구가 필요한 단계라고 할 수 있다.
| |
| |
| |
| |
|

|
|
| 관련뉴스 | - 관련뉴스가 없습니다. |














|
||||||||||||||||||||||||
|