













엔비디아, MoE 아키텍처로 최첨단 AI 모델 성능 혁신
등록일 2025년12월04일 12시10분








엔비디아가 최첨단 AI 모델들이 채택하고 있는 전문가 혼합 방식(mixture-of-experts, MoE) 모델 아키텍처의 성능을 극대화하는 '엔비디아 블랙웰 GB200 NVL72(NVIDIA Blackwell GB200 NVL72)'의 기술적 성과를 공개했다.
오늘날 거의 모든 프론티어 모델의 내부 구조를 살펴보면, 인간 두뇌의 효율성을 모방한 MoE 모델 아키텍처가 적용된다.
두뇌가 작업에 따라 특정 영역만 활성화하는 것처럼, MoE 모델은 작업을 전문화된 '전문가(Experts)'에게 분배해, 각 AI 토큰마다 해당되는 전문가만을 활성화한다. 이로 인해 연산량 증가 없이 더 빠르고 효율적으로 토큰을 생성할 수 있다.
업계는 이미 이러한 장점을 인정하고 있다. 독립 평가 기관인 아티피셜 애널리시스(Artificial Analysis, AA)의 리더보드에서 상위 10개 오픈소스 모델 모두 MoE 아키텍처를 사용하고 있다. 여기에는 딥시크 AI(DeepSeek AI)의 딥시크-R1(DeepSeek-R1), 문샷 AI(Moonshot AI)의 키미 K2 씽킹(Kimi K2 Thinking), 오픈AI(OpenAI)의 gpt-oss-120B, 미스트랄 AI(Mistral AI)의 미스트랄 라지 3(Mistral Large 3) 등이 포함된다.
MoE 모델을 실제 프로덕션 환경에서 고성능으로 확장하는 일은 매우 어렵다. 그러나 엔비디아 GB200 NVL72 시스템의 하드웨어·소프트웨어 초협업 설계(extreme codesign)는 최고 수준의 성능과 효율성을 제공함으로써, MoE 모델 확장을 실용적이고 간편하게 만든다.
AA 리더보드에서 가장 지능적인 오픈소스 모델로 평가된 키미 K2 씽킹 MoE 모델은 엔비디아 HGX H200 대비 엔비디아 GB200 NVL72 랙 규모 시스템에서 10배의 성능 향상을 보인다. 딥시크-R1과 미스트랄 라지 3 MoE 모델에서 입증된 성능을 기반으로 한 이번 성과는 MoE가 프런티어 모델의 표준 아키텍처로 자리 잡고 있음을 보여준다. 또한 엔비디아의 풀스택 추론 플랫폼이 MoE의 잠재력을 온전히 발휘하기 위한 핵심 요소임을 강조한다.
최첨단 모델의 표준이 된 MoE
최근까지 더 똑똑한 AI를 구축하는 업계 표준은 단순히 더 크고 밀도 높은 모델을 만드는 것이었다. 이러한 모델은 모든 토큰을 생성하기 위해 모델 매개변수를 모두 사용한다. 현재 최고 성능 모델의 경우 매개변수는 수백억 개에 달하기도 한다. 이 접근 방식은 강력하지만 막대한 컴퓨팅 파워와 에너지를 필요로 해 확장이 어렵다.
인간의 두뇌가 언어 처리, 사물 인식, 수학 문제 해결 등 다양한 인지 작업을 특정 영역에 의존하는 것과 마찬가지로, MoE 모델은 여러 ‘전문가’로 구성된다. 주어진 토큰에 대해 라우터는 가장 관련성이 높은 전문가들만 활성화한다. 이 설계 덕분에 전체 모델이 수천억 개의 매개변수를 포함할지라도, 토큰 생성에 사용되는 매개변수는 수백억 개 수준의 소수 집합에 그치기도 한다.
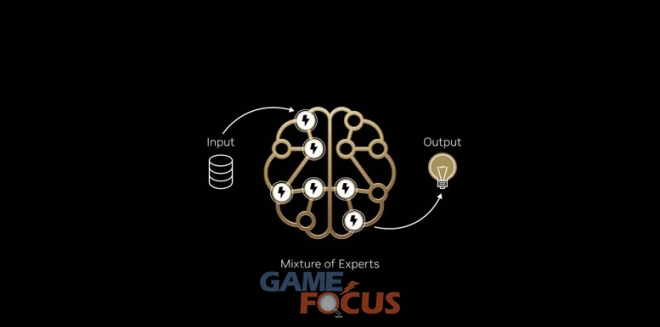
가장 중요한 전문가들만을 선택적으로 활용함으로써, MoE 모델은 계산 비용의 증가 없이 더 높은 지능과 적응성을 달성한다. 이는 성능 대비 비용 또는 전력에 최적화된 효율적인 AI 시스템의 기반이 되며, 투자된 에너지와 자본 단위당 훨씬 더 많은 인텔리전스를 생성한다.
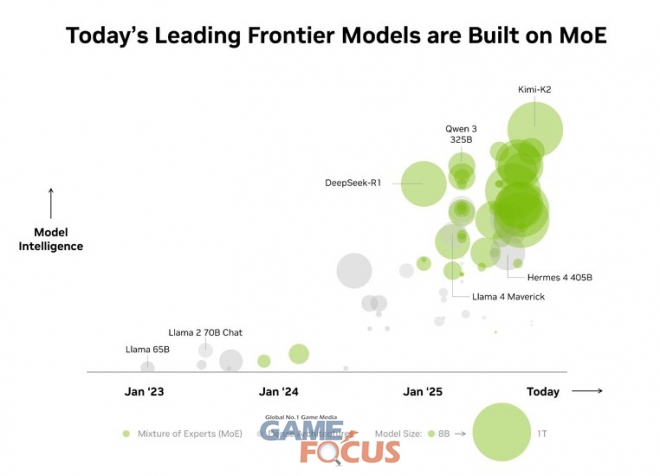
이러한 장점 덕분에 MoE가 최첨단 모델의 선호 아키텍처로 급부상한 것은 당연한 결과이다. 올해 공개된 오픈소스 AI 모델의 60% 이상이 이를 채택했다. 2023년 초 이후 MoE는 모델 지능을 약 70배 향상시켜 AI 능력의 한계를 확장해 왔다.
미스트랄 AI의 공동 창립자이자 수석 과학자인 기욤 람플(Guillaume Lample)은 “2년 전 믹스트랄(Mixtral) 8x7B로 시작한 OSS 전문가 혼합 방식 아키텍처에 대한 우리의 선구적인 작업은 다양한 애플리케이션에 고급 인텔리전스를 접근 가능하고 지속 가능하게 보장한다. 미스트랄 라지 3의 MoE 아키텍처는 에너지와 컴퓨팅 수요를 획기적으로 낮추면서 AI 시스템을 더 높은 성능과 효율성으로 확장할 수 있게 한다”고 말했다.
초협업 설계로 MoE 확장성 병목 현상 극복
프론티어급 MoE 모델은 단일 GPU에 배포하기에는 지나치게 크고 복잡하다. 이를 실행하기 위해서는 전문가들을 여러 GPU에 분산시키는 전문가 병렬 처리 기법이 필요하다. 그러나 엔비디아 H200과 같은 고성능 플랫폼에서도 MoE 모델 배포에는 다음과 같은 병목이 발생한다.
메모리 제약: 각 토큰마다 GPU는 선택된 전문가들의 매개변수를 고대역폭 메모리(HBM)에서 동적으로 불러와야 하며, 이로 인해 메모리 대역폭에 지속적으로 높은 압력이 가해진다.
지연: 전문가들은 정보를 교환해 완전한 답을 형성하기 위해 거의 즉각적인 전면적 통신 패턴을 수행해야 한다. 그러나 H200에서는 8개 이상의 GPU에 전문가를 분산하면 지연이 더 큰 확장형 네트워킹을 통해 통신해야 하므로, 전문가 병렬 처리의 이점이 제한된다.
이 문제를 해결하는 해법이 바로 초협업 설계다.
엔비디아 GB200 NVL72는 72개의 엔비디아 블랙웰 GPU가 하나의 시스템처럼 동작하는 랙 스케일 시스템으로, 1.4엑사플롭스(exaflops)의 AI 성능과 30테라바이트(TB)의 고속 공유 메모리를 제공한다. 72개의 GPU는 NV링크(NVLink) 스위치를 통해 단일 거대 NV링크 상호연결 패브릭으로 구성되며, 이를 통해 모든 GPU가 초당 130테라바이트의 NV링크 대역폭으로 서로 통신할 수 있다.
MoE 모델은 이러한 설계를 활용해 전문가 병렬 처리를 이전의 한계를 훨씬 넘어 확장할 수 있으며, 전문가를 최대 72개의 GPU에 걸쳐 분산할 수 있다.
이 아키텍처 접근 방식은 다음과 같은 방법으로 MoE 확장성 병목 현상을 직접 해결한다.
GPU당 전문가 수 감소: 최대 72개의 GPU에 걸쳐 전문가를 분산 배치함으로써 GPU당 전문가 수를 줄여 각 GPU의 HBM에 가해지는 매개변수 로딩 부담을 최소화한다. GPU당 전문가 수가 줄어들면 메모리 공간도 확보돼 각 GPU가 더 많은 동시 사용자를 처리하고 더 긴 입력 길이를 지원할 수 있다.
전문가 간 통신 가속화: GPU에 분산된 전문가들은 NV링크를 통해 즉시 상호 통신할 수 있다. NV링크 스위치(Switch)는 또한 다양한 전문가의 정보를 결합하는 데 필요한 일부 계산을 수행할 수 있는 연산 능력을 갖추고 있어 최종 답변 전달 속도를 높인다.

다른 풀스텍 최적화 역시 MoE 모델의 높은 추론 성능을 실현하는 데 중요한 역할을 한다. 엔비디아 다이나모(Dynamo) 프레임워크는 프리필(prefill)과 디코드(decode) 작업을 서로 다른 GPU에 할당하는 분산형 서빙을 조율한다. 이를 통해 디코딩은 대규모 전문가 병렬 처리로, 프리필은 해당 워크로드에 최적인 병렬 처리 기법으로 각각 실행되도록 한다. NVFP4 형식은 정확도를 유지하면서 성능과 효율성을 더욱 향상시킨다.
엔비디아 텐서RT-LLM(TensorRT-LLM), SGLang, vLLM 등 오픈소스 추론 프레임워크는 이러한 MoE 최적화를 지원한다. 특히 SGLang은 GB200 NVL72에서 대규모 MoE 기술을 발전시키는 데 중요한 역할을 했으며, 현재 널리 사용되는 여러 기술을 검증하고 성숙시키는 데 기여했다.
전 세계 기업들에 이 성능을 제공하기 위해 GB200 NVL72는 아마존웹서비스(Amazon Web Services, AWS), 코어42(Core42), 코어위브(CoreWeave), 크루소(Crusoe), 구글 클라우드(Google Cloud), 람다(Lambda), 마이크로소프트 애저(Microsoft Azure), 네비우스(Nebius), 엔스케일(Nscale), 오라클 클라우드 인프라스트럭처(Oracle Cloud Infrastructure), 투게더 AI(Together) AI 등 주요 클라우드 서비스 제공업체와 엔비디아 클라우드 파트너(Cloud Partner, NCP)에 의해 배포되고 있다.
코어위브의 공동 창립자 겸 CTO인 피터 살란키(Peter Salanki)는 “코어위브의 고객들은 에이전틱 워크플로우를 구축하기 위해 전문가 혼합 방식 모델을 프로덕션 환경에서 활용하고 있다. 우리는 엔비디아와 긴밀한 협력을 통해 성능, 확장성, 안정성을 모두 담은 통합 플랫폼을 제공할 수 있게 됐다. 이는 AI 전용으로 설계된 클라우드에서만 가능한 일이다”라고 말했다.
딥엘(DeepL)과 같은 고객사들도 차세대 AI 모델을 구축하고 배포하기 위해 블랙웰 NVL72 랙 스케일 설계를 활용하고 있다.
딥엘 리서치팀 리드인 폴 부쉬(Paul Busch)는 “딥엘은 MoE 모델을 훈련하기 위해 엔비디아 GB200 하드웨어를 사용하고 있으며, 훈련과 추론 효율성을 향상시키는 방향으로 모델 아키텍처를 발전시키고 있다. 이는 AI 성능의 새로운 기준을 제시하는 성과이다”라고 말했다.
성능 대비 전력 효율이 증명하는 결과
엔비디아 GB200 NVL72는 복잡한 MoE 모델을 효율적으로 확장하며, 전력 대비 성능에서 10배 향상을 제공한다. 이러한 성능 향상은 단순한 벤치마크 수치가 아니라, 토큰 처리량을 10배로 끌어올려 전력과 비용 제약이 큰 데이터센터 환경에서 대규모 AI의 경제성을 근본적으로 변화시키는 결과이다.
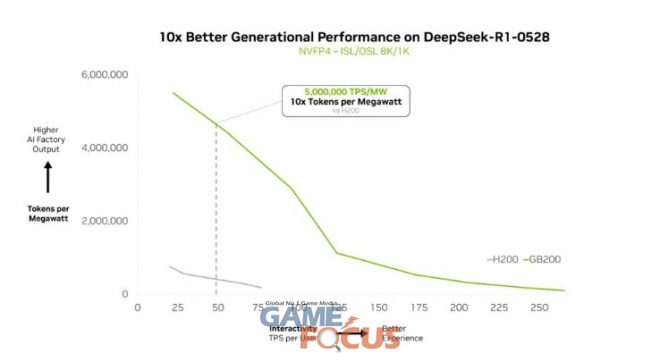
엔비디아 GTC 워싱턴 D.C.(GTC Washington D.C.)에서 엔비디아 창립자 겸 CEO 젠슨 황(Jensen Huang)은 GB200 NVL72가 딥시크-R1 모델에서 엔비디아 호퍼(Hopper) 대비 10배 성능을 제공한다고 강조했으며, 이러한 성능은 다른 딥시크 계열 모델에도 동일하게 적용된다고 밝혔다.
투게더 AI의 공동 창립자 겸 CEO인 비풀 베드 프라카시(Vipul Ved Prakash)는 “GB200 NVL72와 투게더 AI의 맞춤형 최적화를 통해 딥시크-V3와 같은 MoE 모델의 대규모 추론 워크로드에서 고객 기대치를 뛰어넘는 성능을 제공하고 있다. 이러한 성능 향상은 엔비디아의 풀스택 최적화와 투게더 AI의 커널, 런타임 엔진, 추측 디코딩(speculative decoding) 기능 전반에 걸쳐 이뤄낸 추론 혁신의 결합에서 비롯된 것”이라고 말했다.
이러한 성능 우위는 다른 프론티어 모델에서도 뚜렷하게 나타난다.
가장 지능적인 오픈소스 모델로 평가된 키미-K2 씽킹 역시 GB200 NVL72에 배포됐을 때 세대 간 성능이 10배 향상되는 또 하나의 확실한 사례이다.
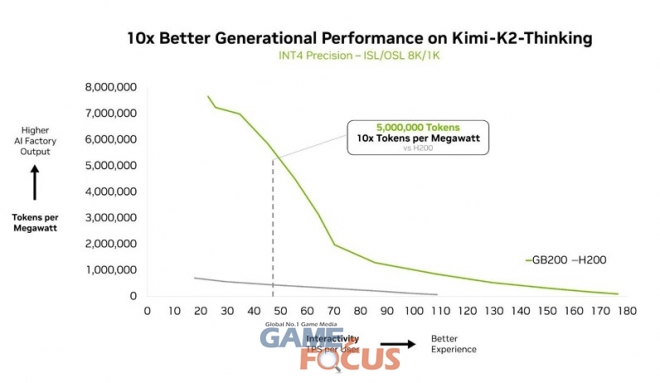
파이어웍스 AI(Fireworks AI)는 현재 엔비디아 B200 플랫폼에 키미 K2를 배포해 AA 리더보드에서 최고 성능을 달성했다.
파이어웍스 AI의 공동 창립자이자 CEO인 린 치아오(Lin Qiao)는 “엔비디아 GB200 NVL72 랙 스케일 설계는 MoE 모델 서비스를 획기적으로 효율화한다. 앞으로 NVL72는 대규모 MoE 모델 서비스 방식을 혁신할 잠재력을 지니며, 호퍼 플랫폼 대비 주요 성능 향상을 제공함으로써 최첨단 모델의 속도와 효율성에 새로운 기준을 제시할 것”이라고 말했다.
미스트랄 라지 3은 GB200 NVL72에서 이전 세대 H200 대비 10배의 성능 향상을 달성했다. 이러한 세대 간 성능 향상은 이 새로운 MoE 모델에 대해 더 나은 사용자 경험, 토큰당 비용 절감, 높은 에너지 효율성으로 이어진다.
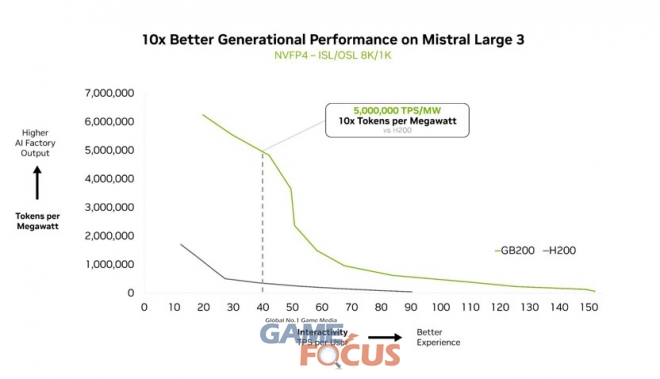
대규모 지능 강화
엔비디아 GB200 NVL72 랙 스케일 시스템은 MoE 모델을 넘어 다양한 AI 워크로드에서 강력한 성능을 제공하도록 설계된 시스템이다.
그 이유는 최신 AI의 발전 방향을 살펴보면 명확하다. 최신 세대의 멀티모달 AI 모델은 언어, 시각, 오디오 등 각 모달리티에 특화된 구성 요소를 갖추고 있으며, 해당 작업에 필요한 구성 요소만 선택적으로 활성화한다.
에이전틱 시스템에서도 마찬가지이다. 각기 다른 ‘에이전트’가 기획, 인식, 추론, 도구 활용, 검색 등 특정 기능을 담당하고, 오케스트레이터가 이를 조율해 하나의 결과를 만들어낸다. 이 두 경우 모두 근본적인 패턴은 MoE와 동일하며, 문제의 각 부분을 가장 적합한 전문가에게 라우팅한 뒤 이들의 출력을 결합해 최종 결과를 도출한다.
이 원칙을 다수의 애플리케이션과 에이전트가 여러 사용자를 동시에 지원하는 프로덕션 환경으로 확장하면 새로운 수준의 효율성을 확보할 수 있다. 개별 에이전트나 애플리케이션마다 거대한 AI 모델을 중복해 운영하는 대신, 모든 요청이 적절한 전문가에게 라우팅되는 방식으로 공유 전문가 풀을 활용할 수 있기 때문이다.
MoE는 막대한 성능, 효율성, 확장성이 공존하는 미래를 향해 업계를 이끄는 강력한 아키텍처이다. GB200 NVL72는 오늘날 이러한 잠재력을 실현하며, 엔비디아의 베라 루빈(Vera Rubin) 아키텍처 로드맵은 프런티어 모델의 가능성을 더욱 확장해 나갈 예정이다.
여기에서 GB200 NVL72가 복잡한 MoE 모델을 어떻게 확장하는지에 대한 상세 기술 분석을 확인할 수 있다.
엔비디아 띵크 스마트(Think SMART)는 엔비디아 풀스택 추론 플랫폼의 최신 혁신을 통해 선도적인 AI 서비스 제공업체, 개발자, 기업이 추론 성능과 투자 대비 수익(ROI)을 향상시킬 수 있는 방안을 다루는 시리즈이다.
| |
| |
| |
| |
|

|
|
| 관련뉴스 | - 관련뉴스가 없습니다. |














|
||||||||||||||||||||||||
|